在 2012 年之前,舉世聞名的 ILSVRC (ImageNet Large Scale Visual Recognition Challenge) 電腦視覺競賽,一直都由 SVM 等傳統方法獲得冠軍,錯誤率大概都落在 25% 左右。然而一個來自多倫多大學的團隊改變了這個現狀。
2012 年, Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 等人帶著他們設計的深度學習模型 AlexNet 參與了這項競賽,並以僅約 15% 的錯誤率獲得冠軍,同時也震驚了電腦視覺學界。
AlexNet 由 5 個卷積層與 3 個全連接層組成,並不複雜,但同時又做了幾大創新
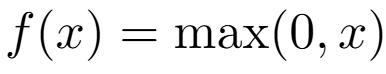
ReLU 不僅計算速度快,而且有效緩解了梯度消失問題,使得訓練更深的網路成為可能。
Dropout:為了防止模型在龐大的數據集上發生過擬合 (overfitting),AlexNet 在全連接層中引入了 Dropout 技術。在訓練過程中,Dropout 會以一定的機率,隨機地「丟棄」一部分神經元、使其輸出為 0。這強迫網路不能過度依賴任何一個單獨的神經元,而是要學習到更穩健、更具泛化能力的特徵組合。
使用 GPU 進行並行計算:ILSVRC 訓練集達 120 萬張圖片,此訓練量在當時是難以想像的。AlexNet 的團隊創造性地使用了兩塊 NVIDIA GTX 580 GPU 進行並行訓練,將網路的不同部分分別放在兩塊 GPU 上(因為數據量太大)。這個舉動不僅讓訓練成為可能,也開創了使用 GPU 加速深度學習訓練的先河。
數據增強 (data augmentation):為了進一步擴充訓練數據,防止過擬合,他們使用了大量的數據增強技巧,如隨機裁切、水平翻轉和顏色抖動。
在 AlexNet 取得成功後,研究人員思考一個問題:是不是網路越深,效果就越好?VGGNet 就是對這問題給出的一個答案。
VGGNet 的所有卷積層,都嚴格地使用了同樣大小的 3×3 卷積核和同樣大小的 2×2 最大池化層,而拋棄了其他花俏的結構。團隊發現,兩個連續的 3×3 卷積層,其感受域等效於一個 5×5 的卷積層;三個連續的 3×3 卷積層,其感受域等效於一個 7×7 的卷積層。但使用多個小的卷積核又有一些好處
引入更多非線性:每經過一個卷積層,就會跟一個 ReLU 激活層。三個 3×3 卷積層意味著有三次非線性變換,而一個 7×7 卷積層只有一次。這使得網路的學習能力更強。
參數更少:假設輸入輸出通道數均為 C,三個 3x3 卷積層的參數是 3 × (3 × 3 × C × C) = 27×C^2,而一個 7 × 7 卷積層的參數是 1 × (7 × 7 × C × C) = 49 × C^2。參數更少,意味著模型更輕量,也更容易訓練。
VGGNet 憑藉這種簡單的堆疊方式,成功地將網路深度擴展到了16層 (VGG-16) 和19層 (VGG-19),並在 2014 年的 ILSVRC 競賽中取得了亞軍。
首先安裝 requests
pip install requests
import torch
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
import json
import requests
from io import BytesIO
# --- 1. 載入預訓練的 VGG-16 模型 ---
# pretrained=True 會自動下載並載入在 ImageNet 上訓練好的權重
print("正在下載並載入預訓練的 VGG-16 模型...")
vgg16 = models.vgg16(pretrained=True)
# 將模型設為評估模式
vgg16.eval()
print("模型載入完成!")
print("\nVGG-16 網路結構:")
print(vgg16)
# --- 2. 準備輸入圖片與預處理 ---
# 定義 ImageNet 的標準化參數
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 使用一張網路圖片進行測試
image_url = "https://images.pexels.com/photos/1108099/pexels-photo-1108099.jpeg"
response = requests.get(image_url)
img_pil = Image.open(BytesIO(response.content))
# 預處理圖片並增加一個 batch 維度
img_tensor = preprocess(img_pil)
batch_t = torch.unsqueeze(img_tensor, 0)
# --- 3. 進行預測 ---
with torch.no_grad():
output = vgg16(batch_t)
# --- 4. 解讀輸出結果 ---
# 下載 ImageNet 的類別標籤
LABELS_URL = 'https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json'
response = requests.get(LABELS_URL)
class_idx = json.loads(response.text)
# 將 { 'class_id': ['class_code', 'class_name'] } 轉換為 { 'class_id': 'class_name' }
imagenet_labels = {int(k): v[1] for k, v in class_idx.items()}
# 將模型的輸出轉換為機率
probabilities = torch.nn.functional.softmax(output[0], dim=0)
# 找出 Top 5 的預測結果
top5_prob, top5_catid = torch.topk(probabilities, 5)
print("\n--- 預測結果 Top 5 ---")
for i in range(top5_prob.size(0)):
class_name = imagenet_labels[top5_catid[i].item()]
probability = top5_prob[i].item()
print(f"第 {i+1} 名: {class_name:<20} | 機率: {probability:.4f}")
# 顯示圖片 (需要 matplotlib)
import matplotlib.pyplot as plt
plt.imshow(img_pil)
plt.title("Test Image")
plt.axis('off')
plt.show()
結果
--- 預測結果 Top 5 ---
第 1 名: golden_retriever | 機率: 0.8215
第 2 名: clumber | 機率: 0.0482
第 3 名: Labrador_retriever | 機率: 0.0317
第 4 名: cocker_spaniel | 機率: 0.0286
第 5 名: Sussex_spaniel | 機率: 0.0218

